Activation function defines the way the output is manipulated based on the input in a Neural Network. These functions must not only be differentiable but they are also mostly non-linear for determining a non-linear decision boundary using non-linear combinations of the input feature vector and weights. A few options for choosing activation function and their details are as under:
Identify function:
The identity function is the simplest possible activation function 

Step function:
A step function originally used in a perceptron, outputs a certain value if the input value is above a certain threshold and it outputs another value if the input value is below the threshold. A example of this could be a binary step function which is used for binary classification, which outputs 1 if the input is above threshold and otherwise outputs 0. This function can also be used as feature identifiers in which these identifiers outputs a 1 if feature is present and 0 otherwise which can be incorporated in our models.

Logistic function:
Logistic function, kind of sigmoid function can be considered a modification of a step function, with an additional region of uncertainty. They are non-linear function with formula 
TanH function:
Another form of sigmoid function is the hyperbolic tangent function which takes the mathematical form: 
Another kind of sigmoid function is the arctan function where 


Softmax function:
A Softmax function converts a raw value into a posterior probability and it is indeed a probability distribution over K different possible outcomes. The function is given by 
Rectified linear unit (ReLU) function:
Rectified linear unit also called as the ramp function is computed as 
A smooth appromixation to the retifier is the analytic function also called as the softplus function is defined as 
There is one major disadvantage of using ReLU function is that if a large gradient is flowing through a ReLU, that could cause the weights to update in a way that the unit will never activate on any datapoint again and the unit is equivalent to have died. This can be managed in some way by adjusting the learning rate accordingly. However there is another alternative to solve this problem by slightly modifying the ReLU function to something known as the leaky ReLU function. Instead of making the function to equal to 0 when x>0, the leaky ReLU function will have a small negative slope. The mathematical eqvivalent is 
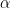
Maxout function:
The maxout activation function computes the maximum of a set of linear functions, and has the property that it can approximate any convex function of the input. The maxout function generalizes the ReLU and leaky ReLU by computing the function 
The best part about modeling is that we have all these functions readily available in libraries today and what we need to know is their application and functioning to apply them correctly for model optimization. As I use python, a few libraries which have inbuilt function to implement all these above activation functions are : Theano, TensorFlow, Keras, Lasagne, MXNet to name a few. Hope you found the article informative. Please do write in your views.
Further read: